想像一家全球電商平台工作。黑色星期五當天,網站同時湧入數百萬使用者,每秒產生數十萬次商品查詢請求。如果每個請求都直接打到資料庫,系統會在幾秒內崩潰。更複雜的是,你的使用者分布在全球各地,從東京到紐約,從倫敦到雪梨,如何確保每個地區的使用者都能獲得快速且一致的購物體驗?
這就是分散式快取系統要解決的核心挑戰:在保證資料一致性的前提下,實現全球規模的高效能資料存取。
今天,我們將深入探討分散式快取的架構設計,從 Netflix 每秒處理 4 億次請求的 EVCache,到 Uber 支撐 1.5 億次讀取的 CacheFront,看看這些頂尖科技公司如何打造他們的快取基礎設施。
分散式快取系統是現代高併發應用的關鍵基礎設施。它不只是單純的資料快取,而是一個複雜的分散式系統,需要在多個資料中心間協調資料,處理網路分割,保證最終一致性,同時提供毫秒級的回應時間。
無論是社交媒體的動態更新、電商平台的商品資訊,還是影片串流的推薦列表,背後都有分散式快取在支撐。它就像是資料庫前的防護盾,攔截了 90% 以上的讀取請求,讓資料庫能專注於處理真正需要持久化的寫入操作。
分散式快取的核心價值在於將熱點資料保存在記憶體中,提供比磁碟存取快 1000 倍的讀取速度。但這不僅是速度問題,更重要的是如何在分散式環境下保證資料的一致性、可用性和分割容忍性。
功能性需求
非功能性需求
技術挑戰 1:資料一致性 vs 效能權衡
分散式環境下,強一致性需要額外的協調開銷,導致延遲增加 2-5 倍。而最終一致性雖然效能好,但可能導致使用者看到過時的資料。不同業務場景需要不同的一致性保證:金融交易需要強一致性,社交動態可以接受最終一致性,購物車則需要會話一致性。
技術挑戰 2:快取失效的三大難題
快取雪崩(大量鍵同時過期)、快取擊穿(熱點鍵失效)、快取穿透(查詢不存在的鍵)是正式環境的三大殺手。一旦處理不當,可能導致資料庫被瞬間流量擊垮。這不是理論問題,而是每個大型系統都會遇到的實際挑戰。
技術挑戰 3:跨區域同步的延遲與衝突
全球部署意味著要處理跨洋網路延遲(100-300ms)、網路分割、以及併發更新衝突。如何設計一個既能保證資料最終一致,又能提供良好使用者體驗的同步機制?這需要在 CAP 定理的約束下做出明智的權衡。
| 維度 | 主從架構 | 對等架構 | 混合架構 |
|---|---|---|---|
| 核心特點 | 單一主節點處理寫入,從節點提供讀取 | 每個節點都可讀寫,無中心化 | 分層設計,結合兩者優點 |
| 優勢 | 實現簡單,強一致性保證 | 無單點故障,擴展性強 | 靈活度高,可針對性優化 |
| 劣勢 | 主節點瓶頸,故障影響大 | 衝突處理複雜,一致性較弱 | 架構複雜,運維成本高 |
| 適用場景 | 讀多寫少,一致性要求高 | 高可用要求,地理分布 | 大規模複雜業務 |
| 複雜度 | 低 | 高 | 很高 |
| 成本 | 較低 | 中等 | 較高 |
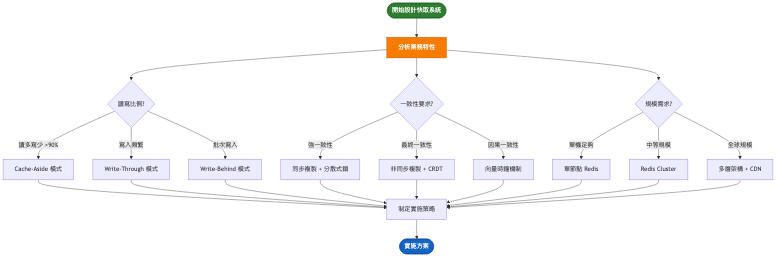
架構重點:
系統架構圖:
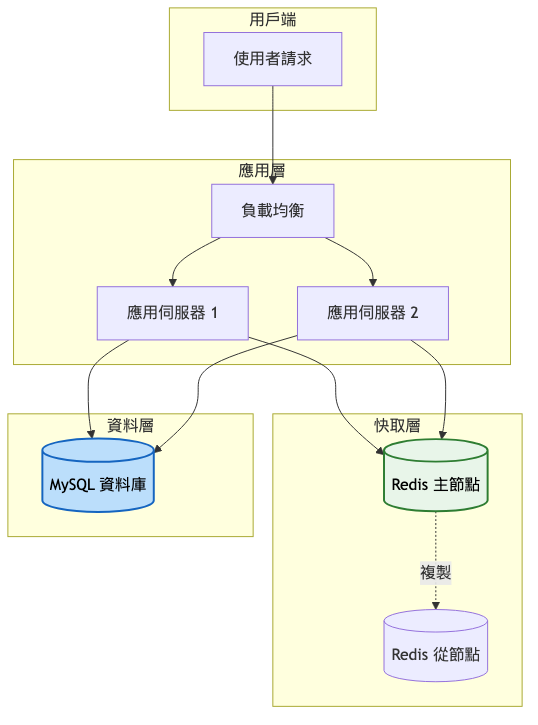
架構重點:
系統架構圖:
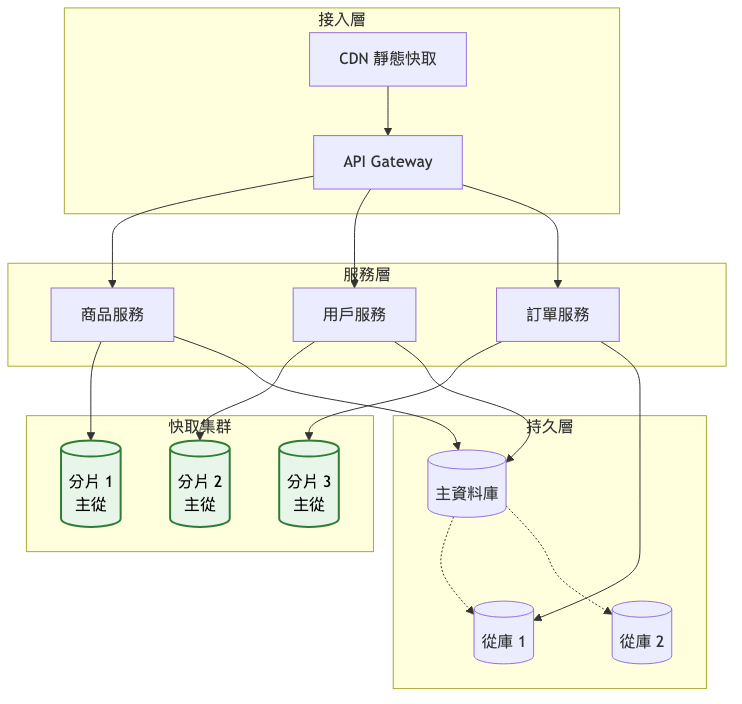
關鍵架構變更:
自動分片機制
快取預熱策略
容錯機制升級
架構重點:
總覽圖:服務分組架構
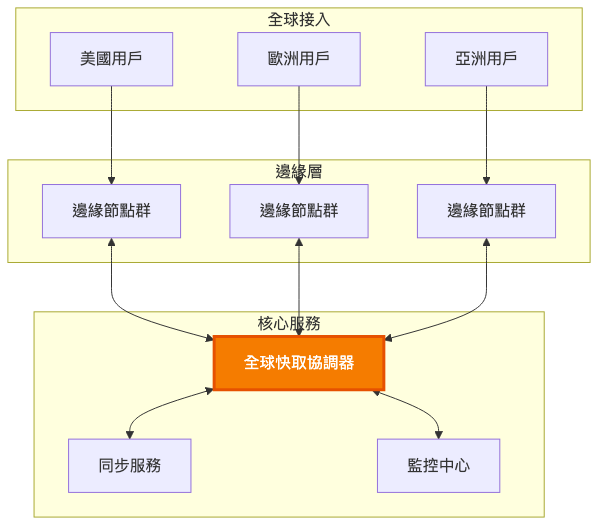
詳細圖:跨區域同步機制
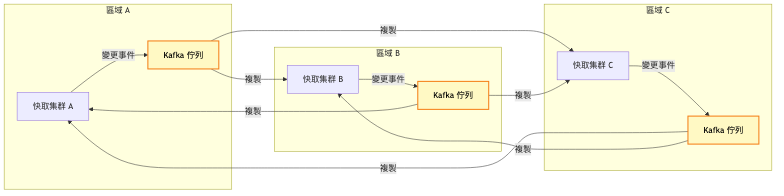
階段演進總覽表:
| 架構特性 | MVP階段 | 成長期 | 規模化 |
|---|---|---|---|
| 架構模式 | 主從複製 | 分片集群 | 多層分散式 |
| 資料分布 | 單一節點 | 自動分片 | 地理分布 |
| 一致性模型 | 強一致性 | 最終一致性 | 混合一致性 |
| 故障恢復 | 手動切換 | 自動故障轉移 | 多區域容災 |
| 監控體系 | 基礎指標 | 全面監控 | 智慧分析 |
| 用戶規模 | < 10萬 | 10萬-100萬 | 100萬+ |
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| 命中率 < 70% | 分析熱點資料,調整快取策略 | 命中率提升至 85%+ |
| P99 延遲 > 10ms | 增加快取節點,優化網路拓撲 | P99 延遲降至 5ms |
| 記憶體使用 > 80% | 水平擴展,增加分片數量 | 記憶體使用降至 60% |
| 跨區域延遲 > 200ms | 部署邊緣節點,使用 CDN | 延遲降至 50ms |
| 資料不一致投訴增加 | 實施向量時鐘或 CRDT | 一致性問題減少 90% |
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Redis Cluster | 成熟穩定、社群活躍、效能極佳 | 資料類型有限、持久化較弱 | 高效能快取、會話儲存 |
| Hazelcast | 分散式計算強、Java 生態友好 | 學習曲線陡、資源消耗大 | 即時計算、記憶體網格 |
| Apache Ignite | ACID 事務、SQL 支援 | 配置複雜、運維成本高 | HTAP 場景、金融系統 |
| Memcached | 極簡設計、記憶體效率高 | 功能單一、無持久化 | 純快取場景、簡單 KV |
| EVCache | Netflix 實戰驗證、跨區域優秀 | 閉源、依賴 AWS | 大規模影片串流 |
技術選型的核心不在於選擇最先進的技術,而在於選擇最適合當前階段的技術。一個成功的分散式快取系統需要經歷多個演進階段:
初期追求簡單可靠,使用成熟的 Redis 主從架構即可。隨著業務成長,逐步引入分片、跨區域複製等複雜特性。關鍵是保持架構的演進能力,每個階段都要為下一階段留出空間。
避免過早優化是重要原則。許多團隊在用戶還不到一萬時就開始設計複雜的多層快取架構,結果反而增加了系統複雜度和運維成本。相反,也要避免技術債務累積過多,當系統出現明顯瓶頸時要果斷升級架構。
快取雪崩的連鎖反應
熱點鍵的效能瓶頸
跨區域同步的資料衝突
快取穿透的資料庫衝擊
Netflix EVCache 的全球架構演進
參考文章:Building a Global Caching System at Netflix
初期(2011-2013)
成長期(2014-2017)
成熟期(2018-現在)
Uber CacheFront 的整合式設計
參考文章:How Uber Serves over 150 Million Reads per Second
Uber 的 CacheFront 展示了另一種設計思路:將快取深度整合到資料存取層。與傳統的獨立快取層不同,CacheFront 作為 Docstore 的一部分,能夠自動追蹤資料變更並維護快取一致性。這種設計實現了 99.99% 的快取一致性,同時支撐每秒 1.5 億次讀取操作。
分散式快取的更新策略決定了系統的一致性和效能特徵。選擇合適的模式需要深入理解業務需求和技術約束。
Cache-Aside 模式最為靈活,應用程式完全控制快取邏輯。適合讀多寫少的場景,但需要處理快取失效和資料庫同步的複雜性。
Write-Through 模式保證強一致性,每次寫入同時更新快取和資料庫。代價是寫入延遲較高,適合一致性要求嚴格的金融場景。
Write-Behind 模式提供最佳寫入效能,先寫快取再非同步寫資料庫。風險是可能丟失資料,適合可容忍短暫不一致的場景。
技術指標:
業務指標:
自動化策略
監控告警
持續優化
分散式快取系統的設計充滿挑戰和權衡。成功的關鍵在於:
針對今天探討的分散式快取系統設計,建議從以下關鍵字深化研究:
一致性雜湊演算法:深入學習 Ketama、Jump Consistent Hash 的數學原理,這是分散式系統的基礎技術。
CRDT 資料結構:掌握無衝突複製資料類型的設計原理,它們提供了解決分散式一致性的優雅方案。
Raft 共識演算法:理解分散式共識的本質,Raft 比 Paxos 更容易理解和實現。
向量時鐘機制:探索邏輯時鐘的概念,理解分散式系統中的因果關係追蹤。
布隆過濾器原理:學習機率型資料結構,在空間和準確性之間的權衡藝術。
這些概念不僅適用於快取系統,更是構建任何分散式系統的基石。
明天我們將探討「多租戶 SaaS 平台」的設計。如何在共享資源的同時確保租戶隔離?如何實現彈性的資源配額管理?如何支援客製化需求而不影響標準化服務?
我們將從 Salesforce、Shopify 等成功案例學習,探討多租戶架構的設計模式、資料隔離策略、以及成本優化方案。這將是一個充滿商業價值的架構挑戰。


 iThome鐵人賽
iThome鐵人賽